
How I'm Using Claude (and Watching My Tokens Disappear in Real Time)
Notes from a heavy Claude user: the page Anthropic doesn't advertise, the API trick that buys me runway, and the real cost of hitting limits.

One thing I’ve noticed using Claude heavily over the last several days: it’s really easy to burn through tokens. Faster than I expected.
I’m on the Pro plan, and I’ve been keeping a close eye on my usage. If you didn’t know this (and a lot of people I talk to don’t), you can actually monitor your Claude usage in real time at claude.ai/settings/usage. I’ve been checking it constantly.
What the Usage Page Actually Shows
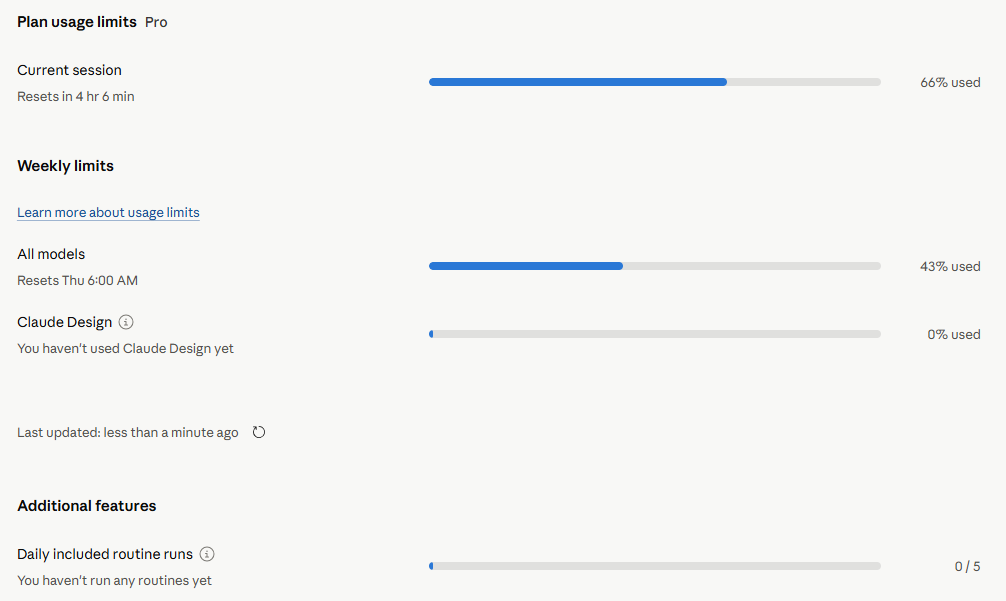
The page breaks your usage into three buckets, which is genuinely useful once you understand what you’re looking at:
Current session limits, your rolling 5-hour window
Weekly limits across all models, the broader ceiling that resets seven days after your session starts
Claude Code plus additional features, a separate bucket that accounts for things like agentic runs
Right now my current daily limit is at 66% and my weekly limit is at 43%. Watching those numbers tick up in real time has actually changed how I prompt. I’m more deliberate. I start fresh chats more often instead of letting one giant thread balloon. Long threads burn tokens faster because Claude has to re-read the whole conversation every turn.
The “Extra Usage” Toggle
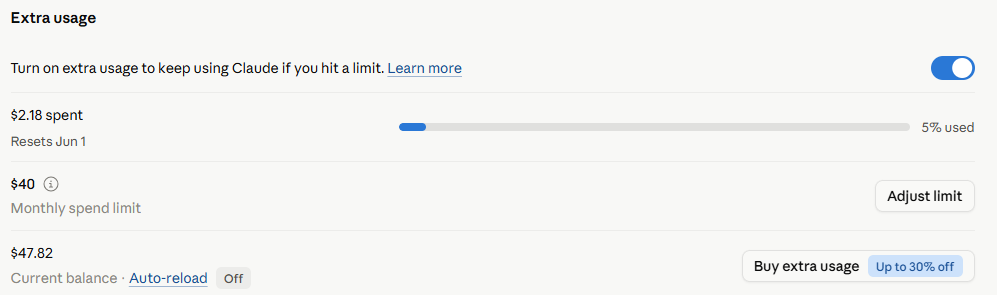
I’ve also turned on extra usage. This is the setting that lets you keep going after you hit your plan’s limit. Instead of stopping cold, you opt in to continue at standard API rates with a monthly spend cap you control.
I turned it on because I’m still on Pro and I’m not quite ready to jump to Max. Hitting a wall mid-session and having to wait it out kills momentum. Paying a little for overflow felt like the right tradeoff for now.
How I Balance Load Across Claude: Using the API for Claude Code
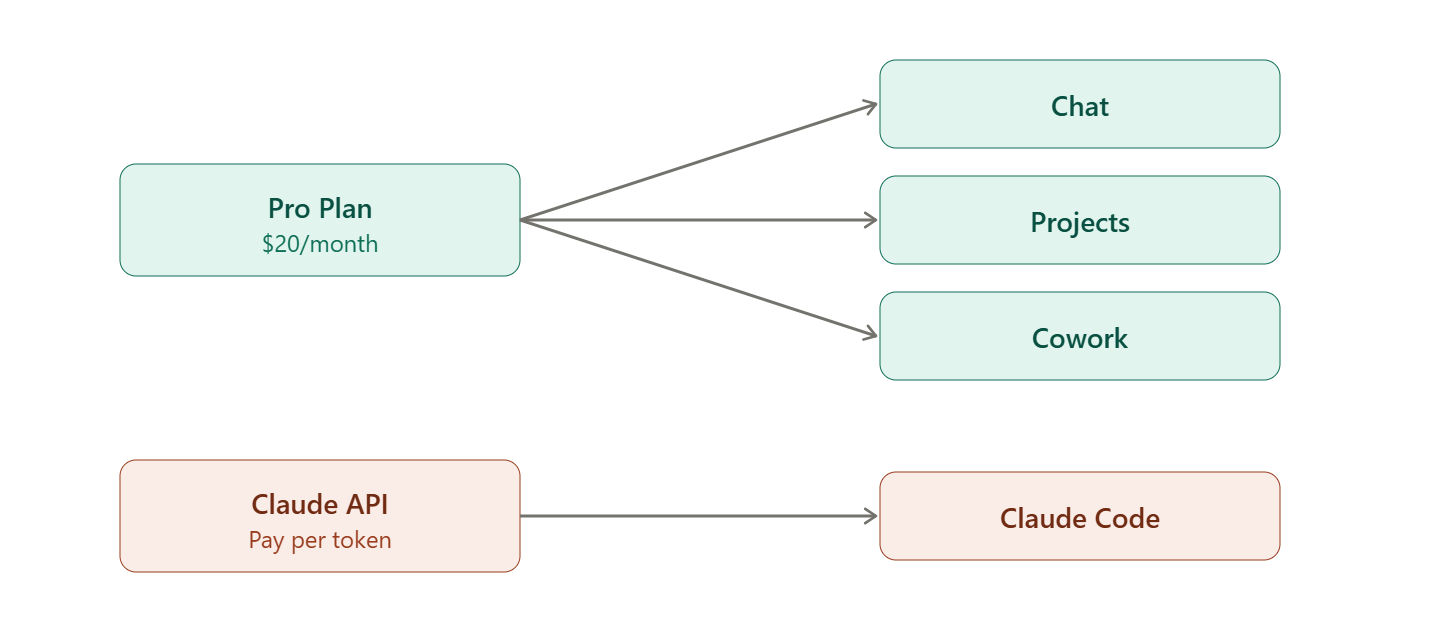
Here’s a strategy I’ve landed on that works well: I use the Claude API for Claude Code, separate from my Pro subscription.
Pro covers chat, Projects, and Cowork, all of which share the same usage pool. Claude Code is the heaviest token consumer in my workflow by a wide margin, so if I run it through the same Pro plan, it eats my limits before I’ve done anything else.
By routing Claude Code to the API and paying per-token, I keep all the other surfaces (chat, Projects, Cowork) running smoothly inside my Pro budget. Yes, the API is more expensive in the moment, but it means I’m not hitting walls across the entire Claude ecosystem just because I had one heavy coding session.
It’s basically load balancing for my own usage.
Tips to Stretch Your Tokens
A few habits I’ve picked up that genuinely help:
Use Projects. This is my biggest one. I love Projects. They’re a great way to save context, build “experts” for specific topics, and store examples of the kind of output you want. Instead of pasting the same long context into every new chat, you set it once and Claude carries it forward. Massive token savings, plus way better answers.
Start fresh chats more often. A long thread isn’t free. Claude re-reads the whole history every turn. When you’ve shifted topics, open a new conversation.
Don’t paste the same document twice. If you’re going to reference it again, that’s what Projects are for.
Use the right model for the job. Not everything needs the most powerful model. Routine reformatting, quick lookups, and simple Q&A don’t need to burn through your premium budget.
Watch the usage page before big sessions. If you’re at 70% on a Tuesday, plan accordingly.
Why I Haven’t Upgraded to Max Yet
The honest reason - I already pay for a lot of AI tools.
ChatGPT (OpenAI)
Gemini
Grok
n8n
ElevenLabs
OpenRouter credits
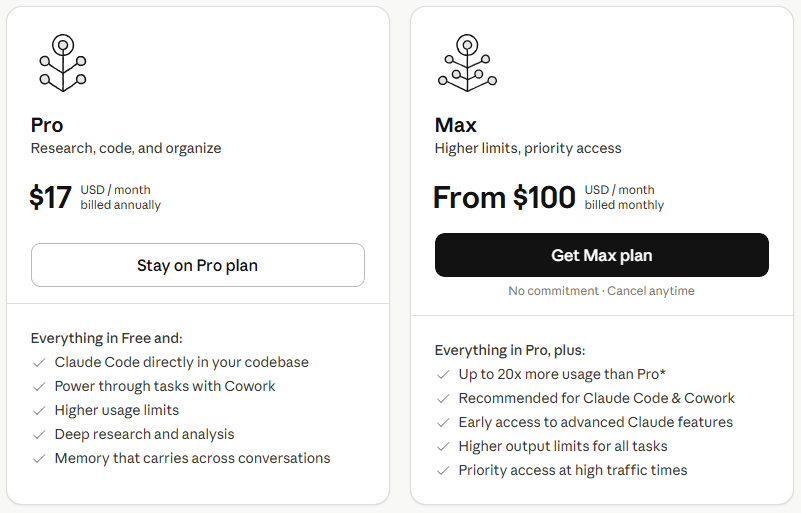
Adding another $100 to $200 per month on top of all that has been a hard sell. For context, Claude Max comes in two tiers: Max 5x at $100/month (5x the usage of Pro) and Max 20x at $200/month (20x the usage of Pro).
What I Actually Use Each Tool For
I get asked this a lot, and the answer isn’t a clean one. Part of the reason I have all these subscriptions is that I genuinely want to try different things in each. But here’s how it’s shaken out in practice:
Claude. Claude Code is where it really shines for me right now. That’s my main use case.
ChatGPT. I find it very useful for Codex. Different strengths, different workflow.
Gemini. This is my daily Q&A app on my phone. I’ve basically replaced Google search with Gemini. When I need to answer something on the go, I’m opening Gemini, not Google.
Grok. I got access through X and don’t use it daily, but I find it refreshing when I want to dig into an area that other apps consider too sensitive or unethical to engage with. Grok doesn’t seem to have those concerns. If I hit a wall on another model, I immediately go to Grok and usually get a great answer.
n8n and ElevenLabs. Totally different use cases (automation and voice respectively). These aren’t really “redundant” with the LLMs. Same will be true for Higgsfield once I add it.
Here’s the thing: the best models from all the major LLM providers are all very good at this point. In theory I could consolidate down to one. But I really don’t want to. I have legitimate use cases for each, and I find it genuinely powerful to have all of them at my disposal.
The Break-Even Math on Max
The math is actually pretty straightforward:
If you’re spending $20/month on Pro plus another $80 or more in extra usage (or API tokens), you should just get Max 5x at $100/month.
That’s exactly where I expect to land. I’m not there today because I bought a chunk of extra usage credits and I want to use those up first. Once I burn through them, I’m 100% switching to Max. Same dollars, fewer interruptions, no per-token accounting in my head.
The Real Cost of Hitting Limits
This is the part nobody talks about enough: the cost of hitting your limit isn’t dollars, it’s momentum.
When you’re deep in a project and Claude tells you to come back in three hours, you don’t just lose those three hours. You lose the mental state you were in. You lose the thread of where you were going. You come back to a project that’s gone cold, and you have to rebuild context for yourself, not just for the model.
This is literally why I bought extra usage credits. Not because I couldn’t afford to wait, but because I couldn’t afford to context-switch. Stopping mid-thought to deal with a usage wall is way more expensive than the $20 or $50 of overflow tokens that would have kept me moving.
If you’re using Claude for real work, that’s the number that should drive your decision, not the sticker price of Max.
Still on the Roadmap
I don’t pay for Higgsfield yet, but that’s the next service on my list to evaluate.
If you’re using Claude more than casually, bookmark the usage page. It’s the difference between guessing what your workflow costs and actually knowing.